Paul,
You mentioned that you are using the “CPU plugin”. Can you provide a link to this specific plugin?
From your query and the output data you shared, I see the following structure for your Influx database:
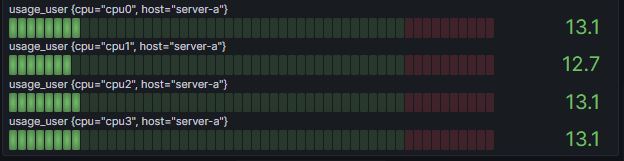
field name: usage_user
field values: 12.670025188917, 12.7401415571282, etc.
measurement name: cpu
tag “cpu” values: cpu-total, cpu0, cpu1, cpu2, cpu3
tag “host” values: server-a
Your flux query will always begin with these 2 lines:
from(bucket: "oracle metrics")
|> range(start: v.timeRangeStart, stop:v.timeRangeStop)
and then follow with a series of Flux filter functions to get the data you want:
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["_field"] == "usage_user")
|> filter(fn: (r) => r["cpu"] == "cpu-total" or r["cpu"] == "cpu0" or r["cpu"] == "cpu1" or r["cpu"] == "cpu2" or r["cpu"] == "cpu3")
|> filter(fn: (r) => r["host"] == "server-a")
and then (optionally) an aggregateWindow function, and a group function to get all of the result tables into one (see the first column of your data…it has 0, 1, 2, 3, 4. If you use a group function, it should put them all to a single result table. The yield is just to deliver the data and is not always needed.
|> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false)
|> group()
|> yield(name: "your-data")
You have a couple of options to display your 4 CPUs (cpu0, cpu1, cpu2, and cpu3):
- Modify the filter function above to filter just the one you want for the given panel. Recreate the query with a different filter setting for a second, third, etc. graph.
- Create a variable in Grafana for the tag values (cpu0, cpu1, cpu2 and cpu3). Then they will be in a dropdown box in Grafana for you to select, and the graph(s) will change accordingly.
- A single graph like you originally shared, but with labels cleaned up. You can use the Organize Fields transformation and possibly some other techniques to get the graph labels correct.
Which of the above are you trying to do?